Built-in AI APIs: usando la IA en la Web

Con la evolución de los diferentes modelos y casos de uso sobre la IA, también aparecen nuevos desafíos y oportunidades. Ya hace un tiempo, así como casi todos en la industria, el equipo de Chrome pensó en integrar un modelo en el browser, pero los grandes modelos son demasiado pesados para el uso personal. Es ahí donde Gemini Nano aparece como una opción viable y donde empiezan a verse formas de conectarse con este modelo, entre ellas las diferentes integraciones en las dev tools así como también las llamadas Built-in AI APIs.
Estas APIs buscan convertirse en un estándar para que desde nuestros sitios web podamos consumir los modelos ya disponibles en el entorno de nuestros usuarios. Con estas APIs, la web está evolucionando hacia un modelo híbrido donde la inferencia no ocurre solo en el servidor.
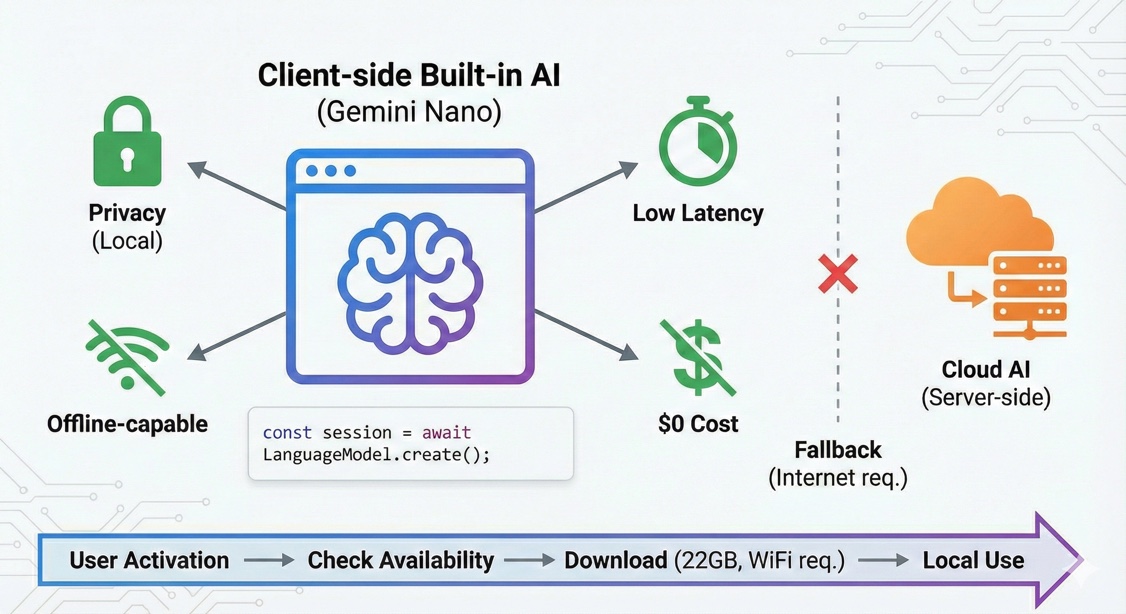
Hasta ahora, la integración de IA implicaba una dependencia estricta de APIs externas: latencia de red, costos por token y riesgos de privacidad. Google está trabajando en cambiar este paradigma con Gemini Nano, un modelo de lenguaje pequeño (SLM) optimizado para ejecutarse localmente en el navegador a través de Chrome.
Este artículo explora la arquitectura técnica de la "Built-in AI", cómo configurar tu entorno de desarrollo, cómo gestionar el ciclo de vida del modelo y las estrategias de fallback necesarias para una experiencia de usuario robusta.
¿Qué es Gemini Nano?
Gemini Nano es un modelo de lenguaje pequeño (SLM - Small Language Model) diseñado por Google para ejecutarse eficientemente en dispositivos con recursos limitados. A diferencia de modelos como GPT-4 o Gemini Pro que requieren clusters de GPUs en la nube, Nano puede correr en la NPU (Neural Processing Unit) o GPU de un laptop o dispositivo móvil moderno.
Capacidades
- Resumen de textos: Hasta ~4K tokens de contexto (~3,000 palabras)
- Reescritura y mejora de contenido: Corrección, reformulación, cambio de tono
- Clasificación: Análisis de sentimiento, categorización, detección de temas
- Traducción básica: Entre idiomas principales (funcionalidad limitada)
Limitaciones Importantes
- No es adecuado para razonamiento complejo: Tareas multipasos o que requieren conocimiento especializado profundo
- Contexto limitado: Comparado con modelos cloud que manejan 100K+ tokens
- Descarga inicial significativa: El tamaño del modelo varía según la versión y optimización, y requiere al menos 22GB de espacio libre en disco para la instalación
- Requiere hardware compatible: Mínimo 8GB de RAM, preferiblemente con GPU dedicada o NPU
El modelo está optimizado para casos de uso donde la privacidad, latencia y disponibilidad offline son más importantes que la capacidad de razonamiento complejo.
Arquitectura: Client-side vs Server-side
La ejecución de modelos en el cliente (Client-side AI) utiliza la NPU (Neural Processing Unit) o GPU del dispositivo del usuario, eliminando la necesidad de servidores de inferencia para tareas específicas.
Comparativa Técnica
| Característica | Server-side AI (Cloud) | Client-side AI (Gemini Nano) |
|---|---|---|
| Latencia | Red + Inferencia (Variable) | Solo Inferencia (Predecible) |
| Privacidad | Datos viajan al servidor | Local-first (Sandboxed) |
| Costo | OpEx (Tokens/Cómputo) | $0 (Hardware del usuario) |
| Disponibilidad | Requiere conexión | Offline-capable |
| Caso de Uso | Razonamiento complejo, RAG masivo | Resumen, reescritura, clasificación |
| Hardware | Infraestructura cloud escalable | Limitado por dispositivo del usuario |
Casos de Uso Prácticos
Cuándo usar Built-in AI (Client-side):
- Resumen de documentos privados (médicos, legales, financieros)
- Asistentes de escritura en tiempo real (corrección, reformulación)
- Clasificación de contenido sin enviar datos al servidor (moderación de comentarios)
- Búsqueda semántica en aplicaciones offline-first (notas, documentos)
- Autocompletado y sugerencias contextuales
Cuándo preferir Server-side:
- RAG (Retrieval-Augmented Generation) con bases de conocimiento extensas
- Modelos especializados fine-tuneados para dominios específicos
- Tareas que requieren razonamiento complejo multipasos
- Análisis que necesita contexto de múltiples usuarios o sesiones
- Procesamiento multimodal complejo (imágenes de alta resolución, video)
Configuración del Entorno (Chrome)
La API aún es experimental y está en pleno proceso de definiciones por lo que hay muchas cosas que pueden cambiar día a día. En general vas a poder acceder a más features en Chrome Canary o Dev pero hay que tener en cuenta que justamente pueden modificarse entre versiones. Para acceder a LanguageModel, necesitas configurar Chrome explícitamente.
Requisitos de Hardware
Antes de comenzar, verifica que tu dispositivo cumple con los requisitos mínimos:
- Almacenamiento: Al menos 22GB de espacio libre en disco (requerido para la instalación del modelo)
- GPU: Más de 4GB de VRAM (NVIDIA, AMD, Intel o NPU dedicada)
- CPU (si no hay GPU): 16GB RAM + 4 o más núcleos
- Sistema Operativo: Windows 10+, macOS 13+, Linux o ChromeOS 16389.0.0+
- Conexión: Red sin límite de datos (unmetered) para descarga inicial del modelo
Nota: En producción, Chrome solo activará la API en dispositivos que cumplan con estos requisitos. Durante el desarrollo usaremos
BypassPerfRequirementpara testear en hardware no certificado, pero el rendimiento puede ser significativamente menor.
Pasos de Configuración
- Versión: Usa Chrome Canary o Dev (versión 128+ recomendada).
- Flags: Navega a
chrome://flagsy configura:chrome://flags/#optimization-guide-on-device-model(Enables optimization guide on device): Enabled BypassPerfRequirement ⚠️ Solo para desarrollo - permite testear en hardware no certificado.chrome://flags/#prompt-api-for-gemini-nano(Prompt API for Gemini Nano): Enabled.
- Reinicio: Reinicia el navegador para aplicar los cambios.
- Verificación de componentes: Navega a
chrome://componentsy busca "Optimization Guide On Device Model". Si no está presente o está desactualizado, haz clic en "Check for update".
Importante: La API está disponible en
localhostdurante desarrollo. Para usar en producción para algunas APIs de momento necesitarás participar en el Origin Trial de Chrome.
Verificación y Descarga del Modelo
A diferencia de una API REST, aquí debemos gestionar el estado del modelo local. El modelo no está presente por defecto; debe descargarse e instanciarse.
1. Detección Básica
Antes de intentar cualquier operación, debemos consultar la disponibilidad del modelo usando el nuevo método availability(). Este método tiene como parámetro la posibilidad de especificar el lenguaje que requerimos, por ejemplo si requerimos inglés y japonés se pasa de parámetro lo siguiente: { languages: ["en", "ja"] }.
// Verificación básica
const availability = await LanguageModel.availability({
languages: ['en', 'es'],
});
if (availability === 'unavailable') {
console.error('Gemini Nano no soportado en este dispositivo');
// Implementar fallback a Cloud API
} else if (availability === 'downloadable') {
console.log('El modelo se descargará en la primera petición');
} else if (availability === 'downloading') {
console.log('El modelo se está descargado');
} else if (availability === 'available') {
console.log('El modelo está descargado y listo para usar');
}⚠️ Requisito Crítico: User Activation
Si el modelo no está descargado (
availability === 'downloadable'), la llamada acreate()iniciará la descarga del modelo y requiere user activation obligatoriamente. Ten en cuenta que la instalación requiere al menos 22GB de espacio libre en disco.Eventos que proporcionan User Activation:
click/tapen un elementokeydown/keypressmousedownVerificación:
if (navigator.userActivation.isActive) { // Seguro llamar a create() const session = await LanguageModel.create(); }Patrón recomendado: Mostrar un botón "Habilitar IA Local" o "Descargar Modelo" que al hacer click inicie la descarga. No intentes descargar automáticamente al cargar la página.
2. Descarga y Monitorización
Si el estado es downloadable, la llamada a create() iniciará la descarga dentro del contexto de un event handler. Es crítico monitorizar este proceso para dar feedback al usuario, ya que la descarga puede tardar dependiendo de la conexión.
Ejemplo básico:
const session = await LanguageModel.create({
monitor(m) {
m.addEventListener('downloadprogress', e => {
console.log(`Descargando: ${e.loaded * 100}%`);
});
},
});3. Verificación de Estado Interno
Si encuentras problemas, estas herramientas de Chrome te ayudarán a debuggear:
chrome://components: Verifica si "Optimization Guide On Device Model" está presente y actualizadochrome://on-device-internals: Logs detallados de inferencia y diagnósticos del modelochrome://chrome-urls/#internal-debug-pages: Habilita páginas internas adicionales para debugging
Tip: Si el modelo no se descarga automáticamente, intenta hacer clic en "Check for update" en
chrome://componentspara forzar la descarga.
Estrategias de Fallback
Una aplicación robusta debe manejar escenarios donde la Built-in AI no está disponible. El patrón recomendado es detectar disponibilidad y degradar graciosamente a una API en la nube.
Patrón Básico
async function summarizeText(text) {
// Intentar usar Built-in AI primero
if (LanguageModel) {
try {
const availability = await LanguageModel.availability({
languages: ['en', 'es'],
});
if (availability !== 'unavailable') {
const session = await LanguageModel.create();
return await session.prompt(`Resume este texto: ${text}`);
}
} catch (error) {
console.warn('Built-in AI falló, usando fallback:', error);
}
}
// Fallback a Cloud API
return await summarizeWithCloudAPI(text);
}Gestión de la Experiencia de Usuario
La descarga inicial del modelo es un punto crítico que puede afectar la percepción del usuario. Hay que recordar que para iniciar la descarga se requiere que ocurra un evento de user activation, por lo que existen dos estrategias principales:
1. Descarga Lazy (On-demand)
Descarga solo cuando el usuario intenta usar una función de IA. Mejor para funcionalidades opcionales. Este enfoque aprovecha el requisito de user activation.
async function handleAIFeatureClick() {
if (!LanguageModel) {
return useCloudFallback();
}
const availability = await LanguageModel.availability({
languages: ['en', 'es'],
});
if (availability === 'downloadable') {
// Mostrar modal explicativo
const userAccepts = await showDownloadDialog({
title: 'Descargar modelo de IA',
message: 'Esta función requiere descargar el modelo para funcionar offline',
benefits: [
'Privacidad: tus datos no salen del dispositivo',
'Funciona sin conexión a internet',
'Respuestas instantáneas',
],
warnings: [
'Requiere al menos 22GB de espacio libre en disco',
'Se recomienda conexión WiFi sin límite de datos',
],
});
if (!userAccepts) {
// Usar cloud API sin preguntar de nuevo
return useCloudFallback();
}
// Mostrar progreso (user activation está activa aquí)
showProgressModal();
await downloadModelWithProgress();
}
// Continuar con la funcionalidad
processWithAI();
}2. Descarga User-initiated (Recomendado)
Permite al usuario decidir cuándo y si descargar. Ideal para dar control total y cumplir con el requisito de user activation.
// En la configuración de la app
function SettingsPanel() {
const [availability, setAvailability] = useState('unknown');
const [downloading, setDownloading] = useState(false);
const [progress, setProgress] = useState(0);
useEffect(() => {
checkAvailability();
}, []);
async function checkAvailability() {
if (!LanguageModel) {
setAvailability('unavailable');
return;
}
const status = await LanguageModel.availability({
languages: ['en', 'es'],
});
setAvailability(status);
}
async function downloadModel() {
setDownloading(true);
try {
await LanguageModel.create({
monitor(m) {
m.addEventListener('downloadprogress', e => {
const percentage = Math.round(e.loaded * 100);
setProgress(percentage);
});
},
});
setAvailability('available');
} catch (error) {
showError(`Error descargando el modelo: ${error.message}`);
} finally {
setDownloading(false);
setProgress(0);
}
}
return (
<div>
<h3>IA Local (Privacidad mejorada)</h3>
<p>Estado: {availability}</p>
{(availability === 'downloadable' || availability === 'downloading') && (
<div>
<button onClick={downloadModel} disabled={downloading}>
{downloading
? `Descargando... ${progress}%`
: 'Descargar modelo de IA'}
</button>
{downloading && (
<div className="progress-bar">
<div style={{ width: `${progress}%` }} />
</div>
)}
<p className="warning">
⚠️ Requiere al menos 22GB de espacio libre en disco y conexión WiFi sin límite de datos
</p>
</div>
)}
{availability === 'available' && (
<div>
<span>✓ Modelo descargado y listo</span>
<button onClick={() => testModel()}>Probar modelo</button>
</div>
)}
{availability === 'unavailable' && (
<div>
<span>⚠️ No disponible en este dispositivo</span>
<p>Usando API en la nube como alternativa</p>
</div>
)}
</div>
);
}Consideraciones generales
Gestión de Memoria
Los modelos ocupan VRAM significativa. Es crítico liberar recursos cuando no se necesitan:
// En React
useEffect(() => {
let session = null;
async function setupAI() {
session = await LanguageModel.create();
}
setupAI();
// Cleanup al desmontar
return () => {
if (session) {
session.destroy();
session = null;
}
};
}, []);También podemos terminar la session usando un AbortSignal.
const controller = new AbortController();
stopButton.onclick = () => controller.abort();
const session = await LanguageModel.create({ signal: controller.signal });Warm-up y Latencia
La primera inferencia puede tener latencia mayor (1-3 segundos) mientras el modelo se carga en memoria. Considera hacer una inferencia "dummy" para warm-up:
async function warmupModel(session) {
// Inferencia pequeña para cargar el modelo en memoria
await session.prompt('test');
console.log('Modelo caliente y listo');
}Restricciones de Producción
Aunque usamos BypassPerfRequirement para desarrollo, en producción Chrome restringirá la disponibilidad basándose en:
- Almacenamiento: Al menos 22GB de espacio libre en disco
- GPU: Más de 4GB de VRAM
- CPU (sin GPU): Mínimo 16GB RAM + 4 núcleos
- Throttling de batería: Puede deshabilitarse en modo ahorro de energía
- User Activation: La descarga del modelo (cuando
availability === 'downloadable') requiere interacción directa del usuario (click, keydown, mousedown)
Por esto es crítico tener una estrategia de fallback robusta. No asumas que la API estará disponible para todos tus usuarios.
Gestión de Tokens
Es importante monitorear el uso de tokens para evitar exceder límites:
console.log(`Tokens usados: ${session.inputUsage}/${session.inputQuota}`);
// Estimar tokens antes de enviar
const estimatedTokens = session.measureInputUsage('Mi prompt aquí');
if (session.inputUsage + estimatedTokens > session.inputQuota) {
console.warn('Prompt demasiado largo, considera crear nueva sesión');
}Streaming de Respuestas
Para respuestas largas, el streaming mejora significativamente la experiencia de usuario al mostrar el texto progresivamente:
// Usar streaming para respuestas largas
const stream = session.promptStreaming('Explica la fotosíntesis en detalle');
// El stream es un ReadableStream
for await (const chunk of stream) {
console.log(chunk);
// Ejemplo: appendToTextArea(chunk);
}Clonación de Sesiones
Para escenarios más avanzados se puede aprovechar y clonar una sesión existente para mantener contexto:
const session1 = await LanguageModel.create({
systemPrompt: 'Eres un asistente experto en JavaScript',
});
// Clonar sesión con su contexto
const session2 = await session1.clone();Agregar Contexto Dinámicamente
Así como podemos clonar una sesión para mantener contexto de forma simple, también podemos añadir contexto a una sesión ya creada:
await session.append([
{ role: 'user', content: 'Necesito ayuda con async/await' },
{ role: 'assistant', content: 'Con gusto te ayudo...' },
]);Configuración de Parámetros
Algo muy interesante de esta API es que nos permite cambiar y obtener los parámetros del modelo para ajustar temperature y topK por sesión:
const params = await LanguageModel.params();
console.log(params);
// {
// defaultTopK: 3,
// maxTopK: 8,
// defaultTemperature: 0.8,
// maxTemperature: 1.2
// }
const session = await LanguageModel.create({
temperature: params.maxTemperature, // Más creatividad
topK: params.maxTopK, // Más diversidad
});Conclusión
Las Built-in AI APIs representan un cambio en cómo podemos integrar IA en aplicaciones web. La capacidad de ejecutar modelos localmente abre nuevas posibilidades para aplicaciones que priorizan privacidad, latencia baja o disponibilidad offline.
Sin embargo, como toda tecnología emergente, requiere un enfoque pragmático:
- Detección de disponibilidad: Siempre verifica
availability()antes de intentar usar la API - Fallbacks robustos: No asumas que todos tus usuarios tendrán acceso al modelo local
- User activation: Respeta el requisito de interacción del usuario antes de iniciar la descarga
- Gestión de UX: Informa claramente sobre los requisitos de espacio en disco (al menos 22GB) y los beneficios
- Monitoreo de recursos: Gestiona memoria y tokens cuidadosamente
Los requisitos de hardware y almacenamiento son significativos, lo que hace aún más importante tener una estrategia híbrida que combine lo mejor de client-side y server-side AI.

