Google ADK: dev experience, testing y debugging

Este es el sexto post de la serie sobre Google ADK. Los anteriores: introducción, setup, FunctionTool, arquitectura multi-agente, y instructions como código.
Desarrollar sistemas de agentes tiene un ciclo de feedback diferente al desarrollo tradicional. No podés hacer un expect(agent.response).toBe("...") — el output no es determinístico. Pero sí podés testear la capa determinística (las herramientas), observar el comportamiento del agente de forma sistemática, y tener confianza razonable en el sistema antes de deployar.
En este post vamos a ver las herramientas de desarrollo que provee ADK, estrategias de testing que funcionan en la práctica, y cómo debuggear los problemas más frecuentes.
adk web — el playground de desarrollo
El comando más importante del ciclo de desarrollo:
npm run dev
# Internamente: npx adk web
# → http://localhost:8000Puede ser que no levante exactamente en esa url, por ejemplo en mi caso, está iniciando en
http://Mac.localdomain:8000. Cuando inicia adk web te indica la url donde está corriendo.
Si navegas al sitio podrás ver una UI que te permite lo siguiente:
Chat en tiempo real con tu agente. Podés mandar mensajes, ver respuestas, y observar el sistema en acción sin ninguna integración adicional.
Trace de ejecución — lo más valioso para debugging. Por cada mensaje del usuario, podés ver exactamente:
- Qué herramienta o sub-agente fue invocado
- Con qué parámetros fue llamada la herramienta
- El resultado que retornó
- Cuántos tokens consumió cada paso
Esto es lo que te permite responder "¿por qué el agente no llamó a la herramienta que esperaba?" o "¿por qué el orquestador delegó al agente equivocado?".
Hot reload — cuando modificás el código, el servidor se reinicia y podés probar los cambios de inmediato sin reiniciar manualmente.
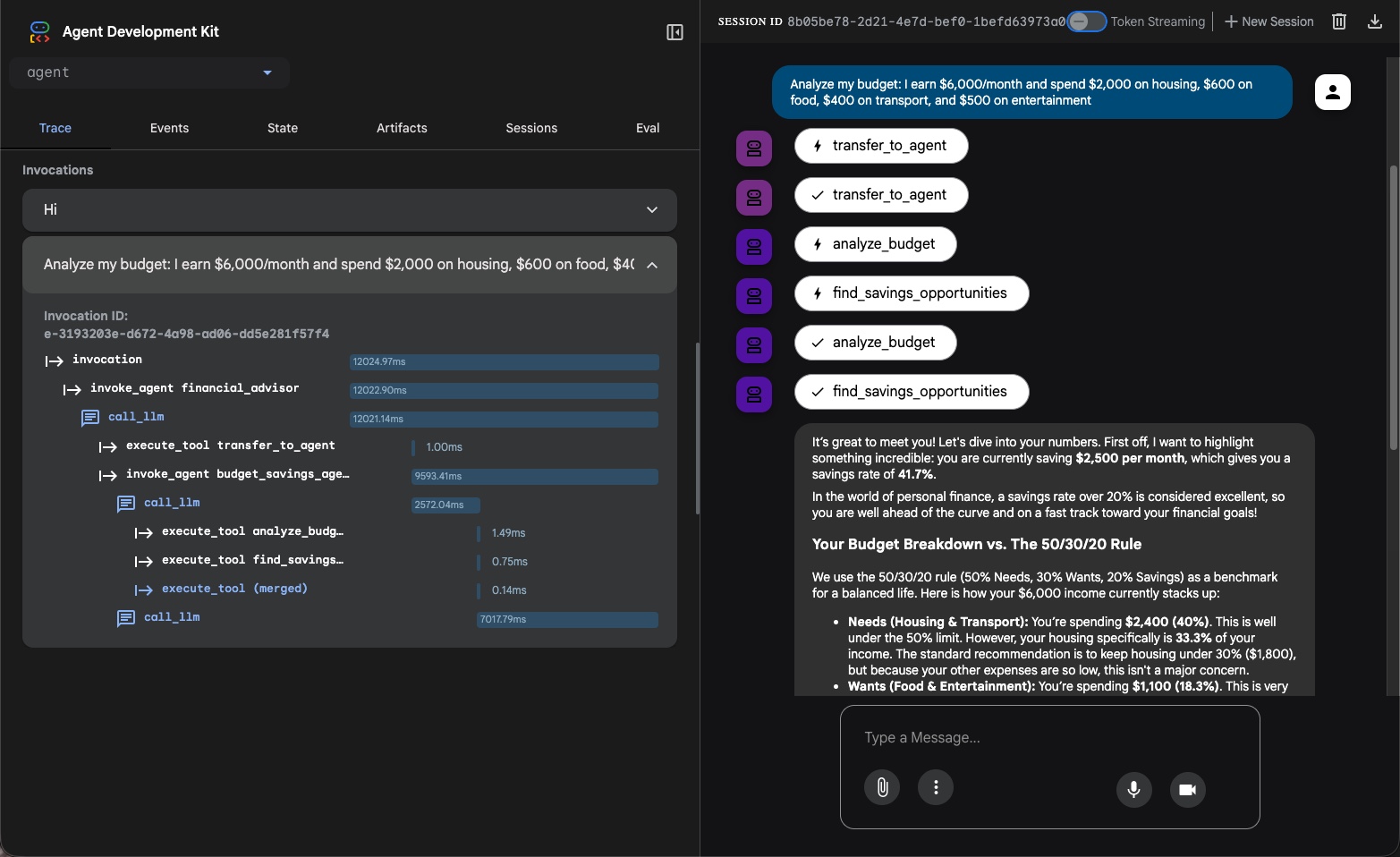
ADK Web en acción
adk run — CLI para scripting y CI
npm run run
# Internamente: npx adk run src/agent.tsAbre un chat interactivo en la terminal. Útil para:
- Testing rápido de un caso específico sin abrir el navegador
- Scripts de smoke testing automatizado
- Entornos donde no tenés browser disponible (CI, SSH remoto)
Estructura de testing para agentes
El stack de testing tiene tres capas con distintos niveles de confianza y velocidad:
Capa 1: Unit tests de herramientas (100% determinístico)
Las herramientas son funciones TypeScript puras. Se testean exactamente igual que cualquier función:
// tests/tools/budgetTools.test.ts
import { describe, it, expect } from 'vitest';
describe('analyzeBudgetTool', () => {
it('calcula la tasa de ahorro correctamente', () => {
const result = analyzeBudgetToolExecute({
monthlyIncome: 5000,
expenses: [
{ category: 'Vivienda', amount: 1500 },
{ category: 'Comida', amount: 400 },
],
});
expect(result.status).toBe('success');
expect(result.summary.savingsRate).toBe('62.0%');
expect(result.summary.currentMonthlySavings).toBe(3100);
});
it('maneja el caso de error graciosamente', () => {
const result = getInvestmentDetailsExecute({ ticker: 'INEXISTENTE' });
expect(result.status).toBe('error');
expect(result.message).toContain('no encontrado');
});
});Esta capa es la más valiosa por costo/beneficio: rápida, sin llamadas a la API de Gemini, y testea la lógica de negocio que más importa.
Un patrón útil para hacer esto mucho mas simple: exportar la función execute separada del FunctionTool, esto hace que resulte mucho mas simple el testing de la función que pasa a ser una función pura de typescript/javascript:
// src/tools/budgetTools.ts
export const analyzeBudgetExecute = (params: {...}) => {
// toda la lógica acá
};
export const analyzeBudgetTool = new FunctionTool({
name: "analyze_budget",
parameters: z.object({...}),
execute: analyzeBudgetExecute,
});// tests/tools/budgetTools.test.ts
import { analyzeBudgetExecute } from '../../src/tools/budgetTools.js';
// Testear directamente sin instanciar FunctionToolCapa 2: Tests de comportamiento de agentes (LLM calls reales)
Estos son más lentos y tienen costo, pero necesarios para validar routing y el comportamiento end-to-end.
InMemoryRunner es un wrapper simple sobre el Runner base que usa implementaciones en memoria para sesiones, artifacts y memoria — no necesitás ningún servicio externo. Lo que no tiene es una API simple de tipo runner.run() que devuelva un objeto con todo resuelto. Lo que devuelve es un stream de eventos que hay que iterar.
El patrón que funciona es armar un helper runAndCollect:
// tests/agents/routing.test.ts
import { InMemoryRunner, getFunctionCalls } from '@google/adk';
import { rootAgent } from '../../src/agent.js';
async function runAndCollect(runner, message) {
const toolCalls = [];
const authors = new Set();
const stream = runner.runEphemeral({
userId: 'test-user',
newMessage: { parts: [{ text: message }], role: 'user' },
});
for await (const event of stream) {
if (event.author) authors.add(event.author);
for (const call of getFunctionCalls(event)) {
if (call.name) toolCalls.push(call.name);
}
}
return { toolCalls, authors };
}getFunctionCalls es una función del SDK que recibe un evento y extrae las tool calls si las tiene. La idea de iterar el stream y acumular en lugar de esperar un resultado final es el modelo de todo ADK — el agente emite eventos a medida que procesa, no un único response al final.
Con ese helper, los tests quedan claros:
describe('routing del orquestador', () => {
let runner;
beforeAll(() => {
runner = new InMemoryRunner({ agent: rootAgent });
});
it('delega análisis de acciones a stock_research_agent', async () => {
const { toolCalls, authors } = await runAndCollect(
runner,
'Analizá los fundamentos de MSFT en detalle'
);
// No chequeamos el texto exacto — chequeamos qué agente actuó y qué herramienta llamó
expect(authors).toContain('stock_research_agent');
expect(toolCalls).toContain('analyze_stock_fundamentals');
}, 30000);
it('delega presupuesto a budget_savings_agent', async () => {
const { toolCalls, authors } = await runAndCollect(
runner,
'Gano $5000/mes. Gastos: Vivienda $1500, Comida $600, Transporte $400'
);
expect(authors).toContain('budget_savings_agent');
expect(toolCalls).toContain('analyze_budget');
}, 30000);
});Dos cosas a notar: el timeout de 30 segundos es necesario porque hay llamadas reales a Gemini, y conviene agregar un guard al principio de la suite para no fallar en CI sin credenciales:
const hasApiKey = !!(
process.env.GOOGLE_API_KEY || process.env.GOOGLE_GENAI_USE_VERTEXAI === 'TRUE'
);
describe.skipIf(!hasApiKey)('routing del orquestador', () => { ... });Capa 3: Smoke tests conversacionales
Para los flujos más críticos, vale tener un set de prompts de referencia y revisar manualmente las respuestas antes de cada release. Un golden dataset de 10-15 prompts con los criterios de aceptación documentados es suficiente para detectar regresiones obvias.
# Smoke Tests — FinancialAdvisorAI
## Routing básico
- [ ] "Analizá AAPL" → debe invocar analyze_stock_fundamentals
- [ ] "¿Cuánto necesito para jubilarme a los 65?" → debe invocar plan_retirement
- [ ] "Tengo $5k de deuda en tarjeta al 19%" → debe invocar analyze_debt_vs_invest
## Casos edge
- [ ] Ticker inexistente ("¿Qué pensás de XYZABC?") → manejo de error amigable
- [ ] Query ambigua ("¿Cómo invierto?") → pedir más contexto antes de recomendar
- [ ] Pregunta sin herramienta obvia ("¿Qué es un P/E ratio?") → responder de conocimiento generalDebugging — los problemas más frecuentes
El agente no invoca ninguna herramienta
Síntoma: el agente responde de memoria sin llamar a ninguna herramienta, aunque debería.
Causa más común: la instrucción no es lo suficientemente directiva. "Podés usar las herramientas disponibles" es diferente a "Siempre usá analyze_budget antes de dar consejos de presupuesto".
Fix:
// ❌ Permisivo — el LLM puede ignorar las herramientas
instruction: `Podés usar analyze_budget para analizar presupuestos.`;
// ✅ Directivo — el LLM tiene que usar la herramienta
instruction: `Siempre llamá analyze_budget cuando el usuario comparta su presupuesto.
Nunca estimes cálculos financieros a mano — usá las herramientas disponibles.`;El orquestador delega al agente equivocado
Síntoma: un query sobre análisis de acciones va a investment_research_agent en lugar de stock_research_agent.
Diagnóstico: abrí el trace en adk web y mirá qué instrucción de routing se activó.
Causa más común: las descripciones de ambos agentes son demasiado similares.
Fix: hacé las descripciones más discriminativas. Agregá negaciones explícitas de lo que el agente NO hace.
// investment_research_agent
description: "Screener de ETFs, overview de mercado, comparación de fondos. " +
"Para análisis PROFUNDO de una acción específica (fundamentals, analistas) → stock_research_agent.",
// stock_research_agent
description: "Due diligence de acciones individuales: fundamentals, analistas, dividendos, técnicos. " +
"Para screening de ETFs o overview de mercado → investment_research_agent.",Las cross-references entre agentes en las descripciones ayudan al orquestador a discriminar.
La herramienta retorna datos que el LLM no usa bien
Síntoma: el agente recibe el retorno de la herramienta pero la respuesta al usuario no refleja los datos.
Causa más común: el retorno tiene demasiada profundidad de nesting o los campos no tienen nombres descriptivos.
// ❌ El LLM puede perderse en el nesting
return {
d: { s: { a: savingsRate, b: totalExpenses }, c: savings },
};
// ✅ Estructura plana con nombres descriptivos
return {
status: 'success',
savingsRate: '18.5%',
totalExpenses: 4100,
currentMonthlySavings: 900,
verdict: 'Tu tasa de ahorro está por debajo del objetivo del 20%',
};Comportamiento inconsistente entre conversaciones
Síntoma: la misma pregunta a veces va a un agente, a veces a otro.
Esto tiene dos causas posibles:
- Instrucciones ambiguas → el LLM tiene margen para interpretar diferente cada vez. Solucionarlo con reglas más explícitas.
- El modelo tiene temperatura > 0 → cierto nivel de no-determinismo es inherente. Para routing crítico podés configurar temperatura 0.
TypeScript como herramienta de debugging
La ventaja de TypeScript es que el compilador te avisa de muchos problemas antes de que lleguen a runtime:
// tsconfig.json
{
"compilerOptions": {
"strict": true,
"noImplicitAny": true,
"noUncheckedIndexedAccess": true
}
}Con noUncheckedIndexedAccess, el compilador te fuerza a manejar el caso de undefined en accesos a arrays — importante cuando iterás sobre resultados de herramientas.
Tipado de los retornos de herramientas:
// Si tipás el retorno, el compilador te avisa si retornás algo incompleto
const retirementPlannerTool = new FunctionTool({
execute: ({ currentAge, retirementAge }): RetirementResult => {
if (retirementAge <= currentAge) {
return { status: "error", message: "La edad de retiro debe ser mayor a la actual" };
}
// TypeScript valida que retornés todos los campos de RetirementResult
return { status: "success", projections: { ... } };
},
});Variables de entorno y configuración por ambiente
El patrón estándar que funciona bien:
// src/config.ts
export const config = {
model: process.env.AGENT_MODEL ?? 'gemini-3-flash-preview',
useVertexAI: process.env.GOOGLE_GENAI_USE_VERTEXAI === 'TRUE',
logLevel: process.env.LOG_LEVEL ?? 'info',
};// src/agents/budgetAgent.ts
import { config } from '../config.js';
export const budgetAgent = new LlmAgent({
model: config.model,
// ...
});Para testing podés setear AGENT_MODEL=gemini-3-flash-preview para reducir costos en los tests que hacen llamadas reales, y el modelo más potente en producción.
El ciclo de desarrollo recomendado
1. Escribir la herramienta (src/tools/)
2. Unit test de la herramienta (tests/tools/) → rápido, sin API calls
3. Probar con adk web → verificar que el agente la invoca correctamente
4. Ajustar instrucciones si el routing o el comportamiento no es el esperado
5. Smoke test manual con casos edge
6. Tests de integración ligeros (opcionales, según criticidad)La mayor parte del tiempo de debugging se va a pasar en el paso 3-4. La UI de adk web con el trace de tool calls es tu mejor aliada ahí.
En el próximo post entramos a producción: cómo containerizar el agente, deployarlo en Cloud Run, manejar secretos con Secret Manager, monitorear con Cloud Logging, y entender el modelo de costos de Gemini para no tener sorpresas en la factura.
Para seguir los ejemplos de testing, el repo en este punto tiene toda la capa de herramientas en
src/tools/lista para testear en unitario. Tambien puedes revisar ejemplos de testing de la lógica de las FunctionTools o el ejemplo de los tests del comportamiento de agentes

